The complete guide to robots.txt file
There are many web robots on the internet. Some of them, known as search engine crawlers, are used by search engines to index pages that are displayed in search results. For such web crawlers, you need a robots.txt file that instructs these crawlers how to crawl your website. What do you need to know about robots.txt files? How can you create and use such a txt file? That’s what we’re going to discuss today.

Generally speaking, the robots.txt file is used by major search engines to index pages within your domain. In fact, that’s the very first resource a web crawler is looking for after arriving at a given website. Why is it so important? Because only indexed pages can rank (be displayed on Google) in this search engine for any query. In other words, if your website wasn’t indexed, it wouldn’t be displayed on Google for any keyword.
Here’s an example of what the robots.txt file looks like:
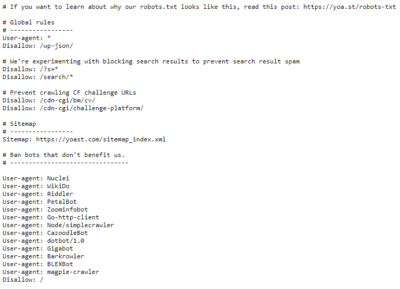
You can view any robots.txt file just by typing this URL address in your internet browser: https://www.domain.com/robots.txt.
As you can see, the robots.txt file doesn’t have to be extensive; you can only include instructions that are vital to you for some reason. You also need to know that not all robots will “listen” to your instructions. In general, all respectable web crawlers usually will obey your instructions, whereas email address scrapers won’t. But it’s still beneficial to include these instructions in your robots.txt file.
To fully understand what robots.txt files actually are, we have to explain a few terms that are not obvious to every web user. Let’s have a look at the most important ones.
PROTOCOLS
The first term we have to explain is protocol. In the digital world, a protocol is a set of instructions and commands. When it comes to the robots.txt file, the most important protocol is known as REP – robots exclusion protocol. It informs Google’s crawler which subpages and resources it should avoid when crawling certain pages. There is also the Sitemaps protocol. It informs search engine crawlers which subpages and resources should be indexed.
USER AGENTS
A user agent is more or less an assigned name for every entity active on the internet. You can use different user agents in your robots.txt file in order to provide specific instructions for different bots crawling your website. To understand how user agents work, let’s use a quick example. Suppose you want your website to be crawled by Google crawlers but not those of other search engines. In such a situation, you can use two sets of instructions (one of which is known as the disallow directive) for web crawlers:
- User-agent: BingbotDisallow: /
- User-agent: GooglebotAllow: /
Shortly put, the disallow directive tells bots not to access the webpage or set of webpages that come after this command.
XML SITEMAP
A sitemap is a short XML (excel) file that contains the list of all the subpages within your entire site. It also comprises so-called metadata (information relating to a specific URL address). You can add your XML sitemap to your robots.txt file to streamline the work of web crawlers. In order to do that, you simply need to add a specific directive:
Sitemap: https://www.example.com/sitemap.xml
Usually, it’s beneficial to place such a command at the end of your robots.txt file.
CRAWL BUDGET AND CRAWL DELAY
This term refers to the number of pages that Googlebot crawls and indexes on your website within a specified time period. If there are more subpages within your domain than Google can crawl, they won’t be indexed on Google, at least not immediately. Here, there is one more term that should interest you. The crawl delay directive instructs crawlers to slow down the crawling process in order not to overload the web server.
How to create a robots.txt file for your website
There are a few principles you have to keep in mind when creating a robots.txt file. First off, don’t use it to create a list of websites that you don’t want to be displayed in Google search results. If you want to do that, go for the “noindex” tag instead. You can also consider securing sensitive data on your website with password protection.
Secondly, you need to understand how search engine spiders interpret the content of your robots.txt file. There are a few rules here.
FILE FORMAT
If you want to create your own file, make sure it’s a standard text file (*.txt) using UTF-8 encoding. Moreover, the lines must be separated by CR, CR/LF, or LF. Additionally, pay attention to the file size. Currently, for Google, it’s 500 kibibytes (KiB) which is the equivalent of 512 kilobytes. You start by creating a robots.txt file on your computer. Once it’s ready, it can be uploaded to your website.
ROBOTS.TXT FILE LOCATION AND NAME
The actual file has to always be located in your website’s top-level directory so that the link leading to it looks like that: https://www.domain.com/robots.txt and not https://www.domain.com/subpage/robots.txt.
The name is also of paramount importance. The “robots.txt” file name is the only one that’s accepted by web crawlers.
SYNTAX
As Google instructs on their website, valid robots.txt lines consist of a field, a colon, and a value. Generally, the format for a command is as follows:
<field>:<value><#optional-comment>
Google supports four types of commands:
- user-agent: identifies which crawler the rules apply to.
- allow: a URL path that may be crawled.
- disallow: a URL path that may not be crawled.
- sitemap: the complete URL of a sitemap.
There is a fifth command that’s frequently used: crawl-delay. It indicates how long a given web crawler should wait before crawling specific page content. For example, if you use the Crawl-delay: 10 command, the crawler should wait for 10 milliseconds to index a specific subpage. Mind you; Google bots don’t recognize this command.
Lines and commands can be grouped together, for example, if they apply to multiple robots, for instance:
- user-agent: e
- user-agent: f
- disallow: /g
If you want to know more, visit the linked website. Most likely, though, if you’ve never created a robots.txt file, you will struggle to create one from scratch. A professional SEO agency, such as Rank Higher Agency, can help you with that! Just reach out to us, and we’ll take care of the rest! You can also follow this comprehensive guide published by Google Search Central.
ONE ROOT DOMAIN AND MORE SUBDOMAINS = MORE ROBOTS.TXT FILES
This refers to domains that have many subdomains. If you have multiple subdomains within your domain (e.g., blog.domain.com, en.domain.com, store.domain.com), each one of them needs a separate .txt file.
TEST YOUR ROBOTS.TXT FILE
Google enables you to verify whether your robots.txt file contains any syntax or logic errors. The Robots.txt tester is available for free, but in order to use it, you need to set up a Google Search Console account for your website.
EASTER EGGS IN ROBOTS.TXT FILES
Many website owners realize that the majority of internet users won’t view the robots.txt file (provided they even know that such files exist!), so they add some easter eggs (humorous messages or lines) into them. For example, Nike’s file starts with the “Just crawl it” command (of course referring to the company’s world-famous slogan) and ends with their logo made of the code lines:
![]()
And here’s another example: Glassdoor.com, an American website with job offers, uses its robots.txt file to encourage potential candidates to apply for a job with their SEO team:
![]()
Summary: Do you have a robots.txt file on your website?
We hope that this article helped you understand what robots.txt files are all about. In general, it’s beneficial to include them on your website. This way, you can streamline the crawling process of your website. And you have the opportunity to provide specific instructions for online crawlers. If you struggle with creating such a file for your website, or you’re not sure what it should include, feel free to contact our team.
We will gladly help you create and optimize a robots.txt file (as well as your XML sitemaps)!